
老规矩,先上成果图,然后放代码,然后写分析过程。
成果图: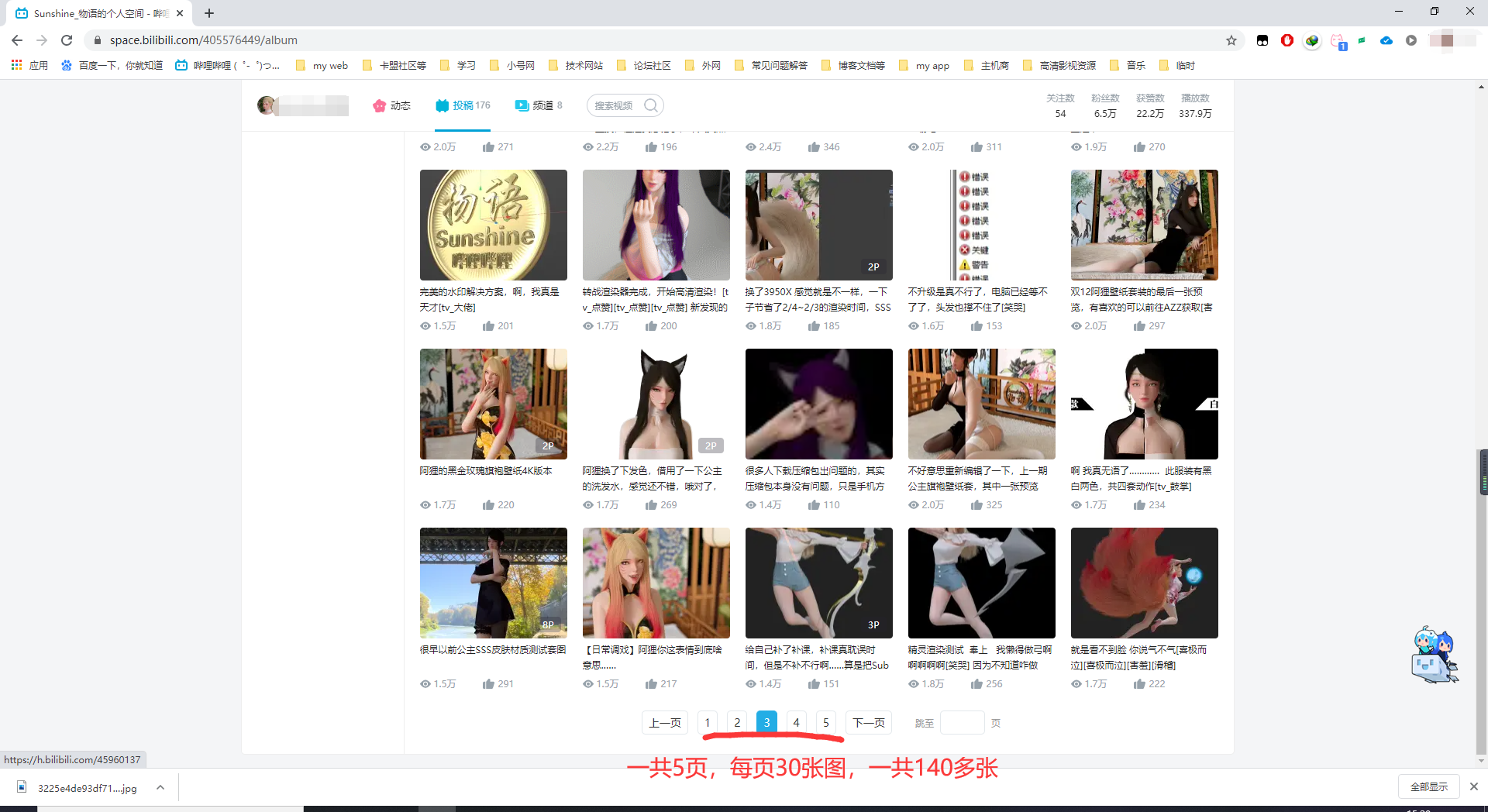

代码如下:
小提示:如果你要直接用代码需在同路径下创建一个名字为”图片“的文件夹,为了省代码我没有写创建文件夹的那一行
import requestsimport jsonheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36'}page = 0 #从第一页开始url = 'https://api.vc.bilibili.com/link_draw/v1/doc/doc_list?uid=405576449&page_num={}&page_size=30&biz=all'.format(page)#第一页链接requests.packages.urllib3.disable_warnings() #这个代码可以去掉,仅仅是为了美观,把警告信息过滤了pic_list = [] #这个列表等会儿用来放图片链接while True: content = requests.get(url, headers=headers, verify=False).content dic = json.loads(content) #将json数据转化为python可以用的字典 if len(dic.get('data').get('items')) == 0: #如果爬完了就停止 break item_list = dic.get('data').get('items') #获取项目信息列表 for i in item_list: i = i.get('pictures')[0].get('img_src') #匹配到图片链接 pic_list.append(i) page += 1 url = 'https://api.vc.bilibili.com/link_draw/v1/doc/doc_list?uid=405576449&page_num={}&page_size=30&biz=all'.format(page)count = 1 #用来计数,顺便给文件命名for pic_url in pic_list: content = requests.get(pic_url, headers=headers, verify=False).content with open('图片/'+str(count)+'.'+pic_url[-3:], 'wb') as f: f.write(content) count += 1接下来就是分析过程:
1.首先打开抓包软件fiddler(这只是我的习惯,其实你不用fiddler直接谷歌浏览器F12也可以的)
2.然后打开谷歌浏览器
3.进入你想要爬取的up主的相册页面,如下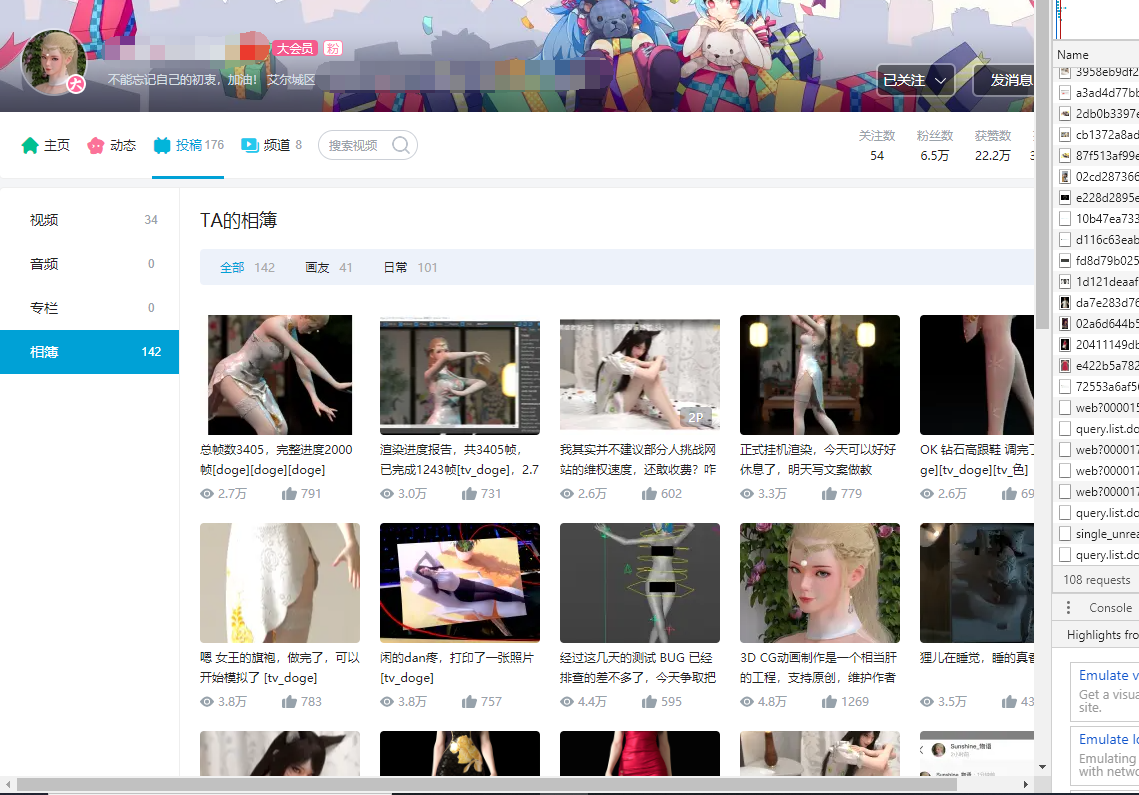
4.打开fiddler查看抓包结果,如图所示,参数很清晰了,我们只需要改变页码即可获取不同页的图片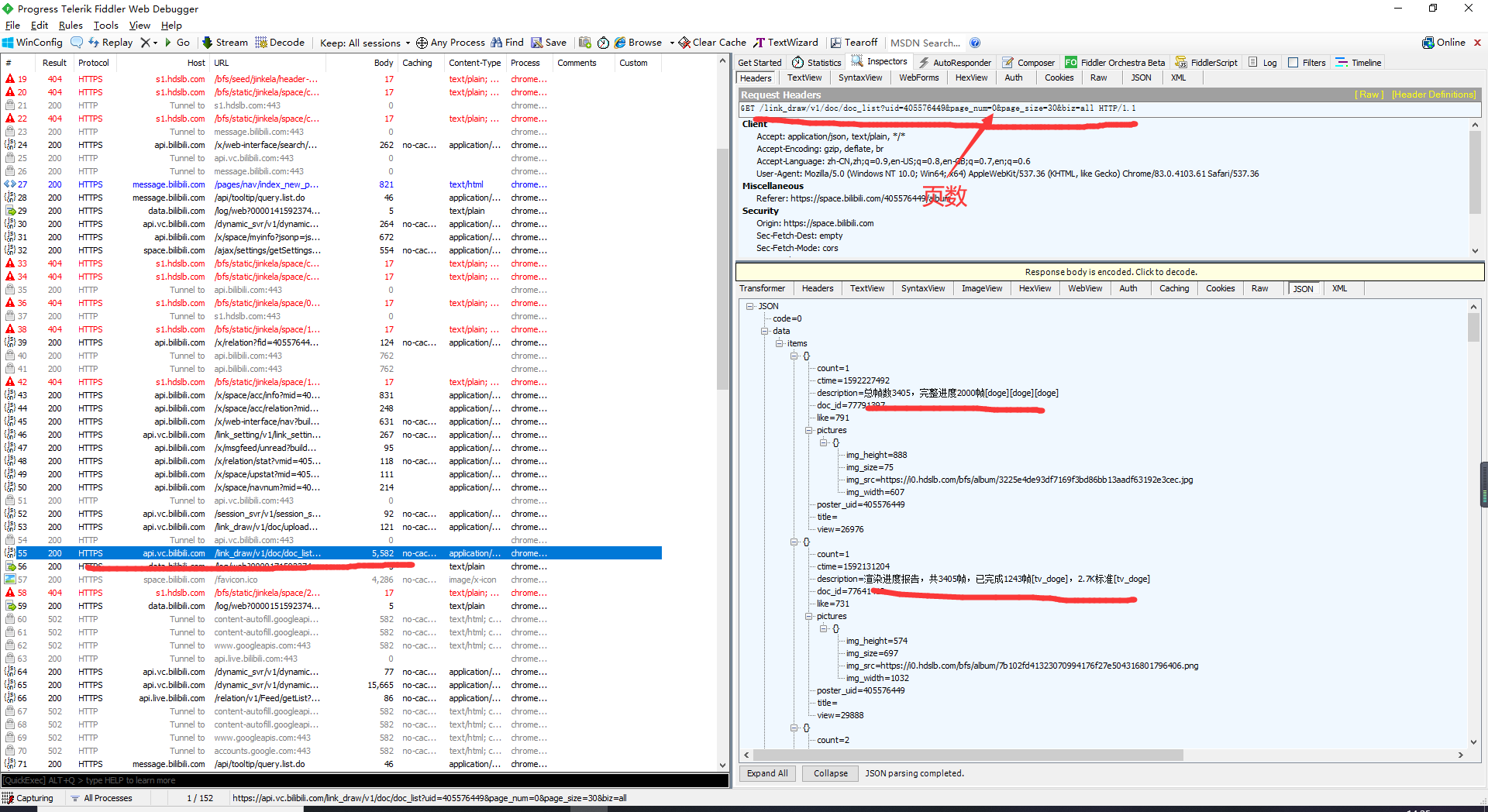
成品在这里:https://www.52pojie.cn/thread-1202189-1-1.html
不过成品的代码比这个源码多4行,有31行,不过也就是一些让用户方便的代码了,比如输入uid和标识出爬取的链接。如果还有不懂的就在楼下留言,我会的基本都会给你解答。
如果觉得有用记得给我一些免费的点赞哦,你们的点赞就是我的动力!
声明:本站所有资源均由网友分享,如有侵权内容,请在文章下方留言,本站会立即处理。