
先上成果图: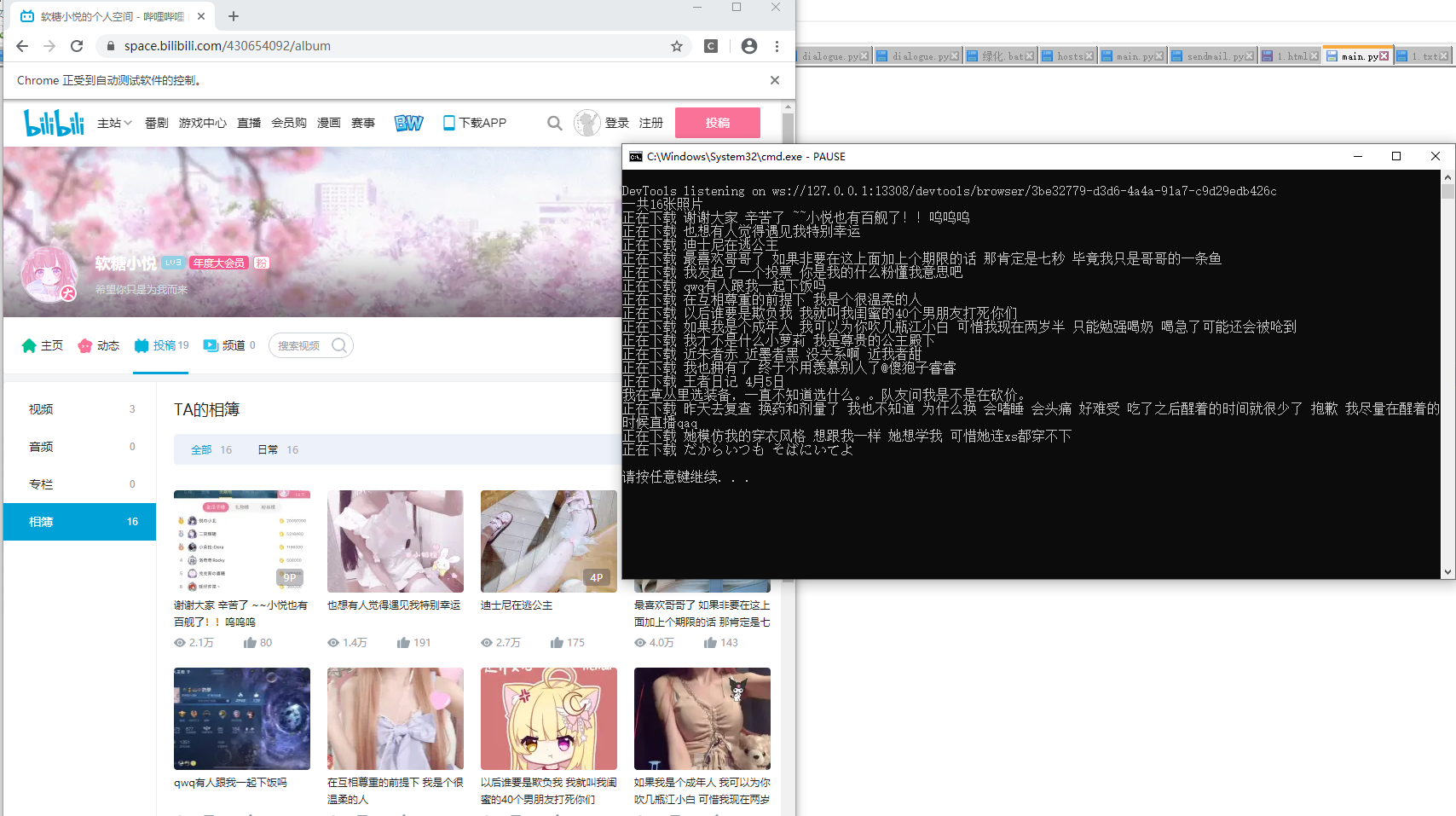
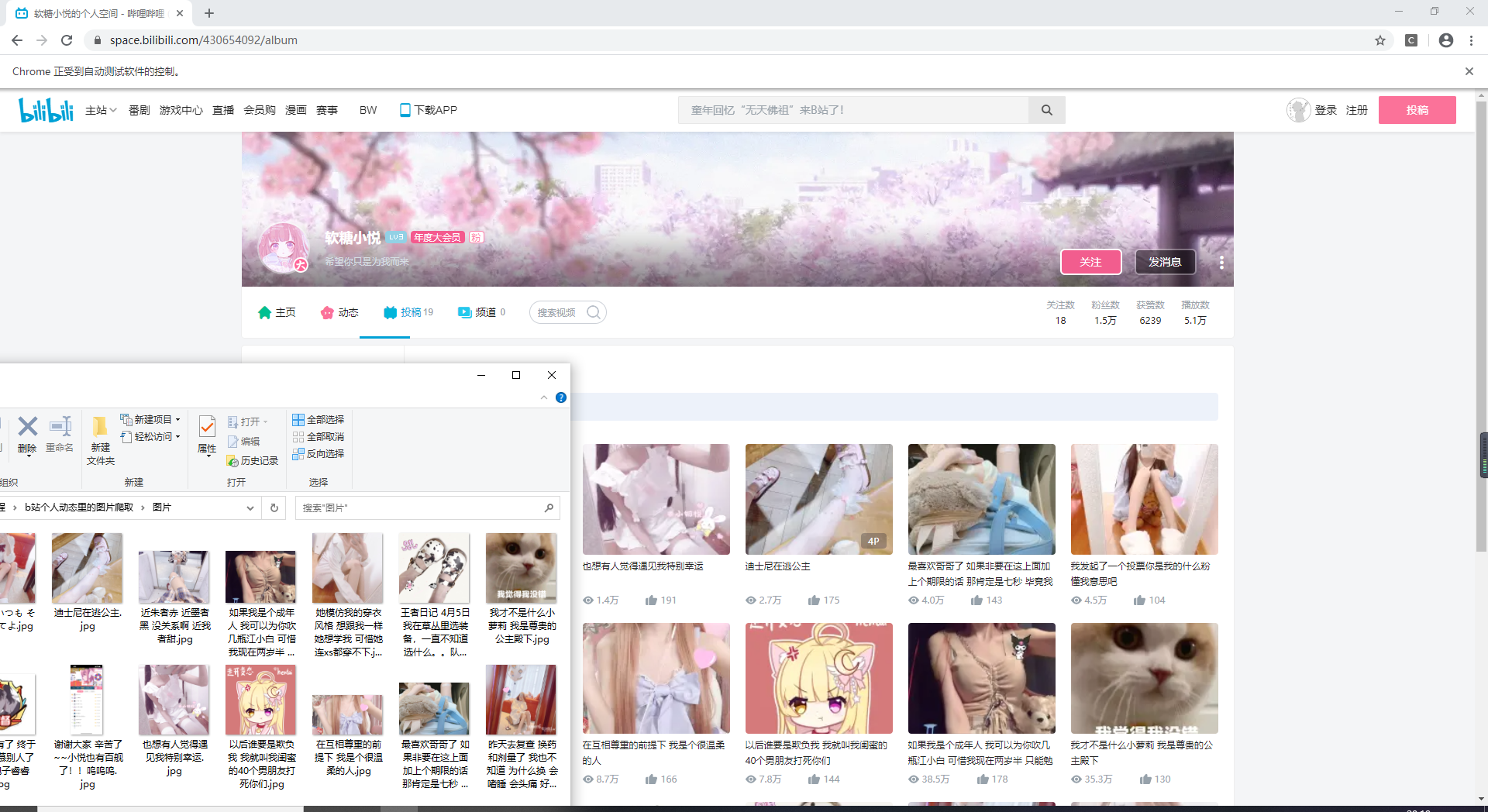
前几天偶然在哄睡区看到一个up主,相册里很多好看的照片,但是一个一个保存太麻烦了,因为如果想保存大图需要点进去才行,于是直接用python写了24行简单的代码,即可轻松爬取。
from selenium import webdriverimport refrom lxml import etreeimport requestsheaders = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36'}driver = webdriver.Chrome()url = "https://space.bilibili.com/430654092/album"pa = re.compile('style="background-image: url\("(.*?)@')driver.get(url)text = driver.page_sourcepic_url_list = pa.findall(text)pic_url_list = pic_url_list[1:]html = etree.HTML(text)titles = html.xpath('//a[@class="title"]/text()')print('一共'+str(len(titles))+'张照片')for pic_url, title in zip(pic_url_list, titles): print('正在下载', title) content = requests.get(pic_url, headers=headers).content if '\n' in title: title = title.replace('\n', '') if '/' in title: title = title.replace('/', '') with open('图片/'+title+'.jpg', 'wb') as f: f.write(content)代码量比较少,我就没有写注释,如果有问题就在贴子下面留言吧。
这里解释一下为什么用selenium而不用requests,因为网站源码是JS动态加载的,直接用requests.get只能得到一点代码,但用selenium就可以完美的得到JS加载后的网页源码了,然后用正则和xpath语法找到高清大图的链接,这时就可以用requests.get来下载图片了,不仅仅是此网站,其他需要动态加载JS的网站也可以。新手爬虫经常会疑惑为什么自己浏览器按F12获取的源码和python里用requests.get获得的源码为什么不一样,这就是原因所在。该方法可以在绝大多数你常用的网站使用。
如果你觉得有用,还请给我一点免费的点赞,谢谢啦
声明:本站所有资源均由网友分享,如有侵权内容,请在文章下方留言,本站会立即处理。